Customer priorities for a modernized data estate are: modernizing on-premises, modernizing to cloud, build cloud native apps and
unlocking insights.
The announcements follow:
SQL Server
2019
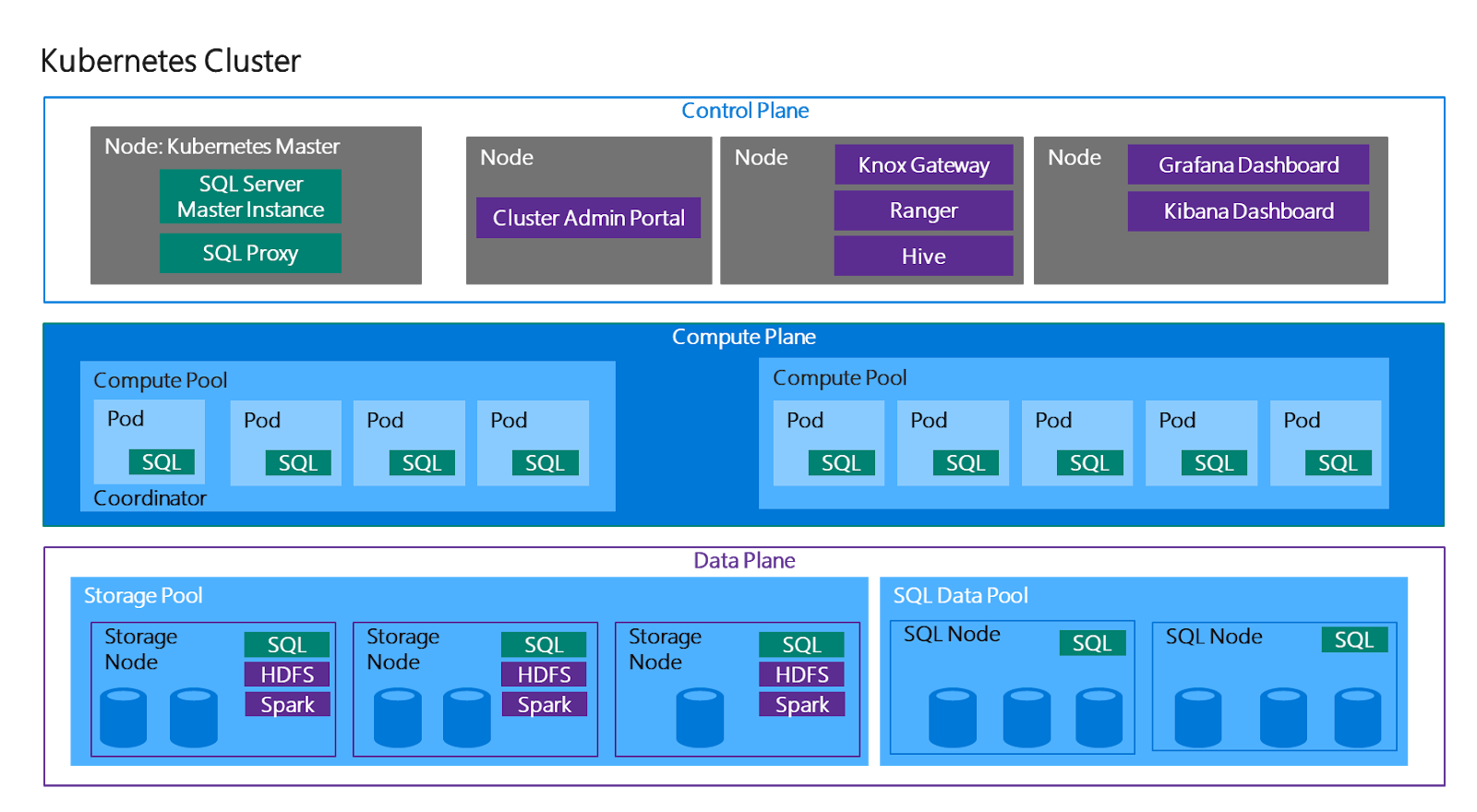
There is the introduction of
big data clusters which combines
Apache Spark and Hadoop into a single data platform called SQL Server. This
combines the power of Spark with SQL Server over the relational and
non-relation data sitting in SQL Server, HDFS and other systems like Oracle,
Teradata, CosmosDB.
There are new capabilities around
performance, availability and security for mission critical environments along
with capability to leverage hardware innovations like persistent memory and
enclaves.
Hadoop, ApacheSpark, Kubernetes and Java are native capabilities in the database engine.
- Fast and consistent Database Recovery
- Instantaneous Transaction rollback
- Aggressive Log Truncation
Azure HDInsight 4.0
There are several Apache Hadoop 3.0 innovations.
Hive LLAP (Low Latency Analytical Processing known as Interactive Query in
HDInsight) delivers ultra-fast SQL queries. The
Performance metrics provide useful
insight.
Data quality and GDPR compliance enabled by Apache Hive
transactions
Improved ACID
capabilities handle data quality (update/delete) issues at row level. This means that GDPR
compliance requirements can now be meet with the ability to erase the data at
row level. Spark can read and write to Hive ACID tables via Hive Warehouse
Connector.
Apache Hive LLAP + Druid = single tool
for multiple SQL use cases
Druid is a high-performance, column-oriented,
distributed data store, which is well suited for user-facing analytic
applications and real-time architectures. Druid is optimized for sub-second
queries to slice-and-dice, drill down, search, filter, and aggregate event
streams. Druid is commonly used to power interactive applications where
sub-second performance with thousands of concurrent users are expected.
Hive Spark Integration
Apache Spark gets updatable tables and ACID transactions with Hive
Warehouse Connector
There are several Apache Hadoop 3.0 innovations.
Hive LLAP (Low Latency Analytical Processing called Interactive Query in
HDInsight) for ultra-fast SQL queries. The
Performance metrics provide useful
insight.
Better data quality and GDPR compliance enabled by Apache Hive
transactions
Improved ACID
capabilities handle data quality (update/delete) issues at row level. GDPR
compliance requirements can now be meet with the ability to erase the data at
row level. Spark can read and write to Hive ACID tables via Hive Warehouse
Connector
Apache Hive LLAP + Druid = single tool
for multiple SQL use cases
Druid is a high-performance, column-oriented,
distributed data store, which is suited for user-facing analytic
applications and real-time architectures. Druid is optimized for sub-second
queries to slice-and-dice, drill down, search, filter, and aggregate event
streams. Druid is commonly used to power interactive applications where
sub-second performance with thousands of concurrent users are expected.
Hive Spark Integration
Apache Spark gets updatable tables and ACID transactions with Hive
Warehouse Connector.
Apache HBase and Apache Phoenix
Apache HBase 2.0 and Apache Phoenix 5.0 get new performance
and stability features and all of the above have enterprise grade security.
Azure
Azure event hubs for Kafka is generally available
Azure Data Explorer is in public preview.
Azure Databricks Delta is in public preview
- Connect data scientist and engineers
- Prepare and clean data at massive scales
- Build/train models with pre-configured ML
Azure SQL DB Managed Instances will be at General Availability
(GA) on Dec 1st. This provides Availability Groups managed by
Microsoft.
Power BI
The new Dataflows is an enabler for self-service data prep in Power
BI
Power BI Desktop November Update
- Follow-up questions for Q&A
explorer. It is possible to ask follow-up questions inside the
Q&A explorer pop-up, which take into account the previous questions you
asked.
- Copy and paste between PBIX files
- New modelling view makes it easier to work with large models.
- Expand and collapse matrix row headers