Hortonworks has announced the general availability of Hortonworks
Data Analytics Studio (DAS). A new service to enable enhanced productivity of business analysts by delivering faster insights from data at scale. DAS is part of the Hortonworks DataPlane Service (DPS). DPS enables businesses to discover, manage, govern and now optimize their data spread across hybrid environments. DAS leverages open-source technologies such as Apache Hive to share and extend the value of a modern data architecture in heterogeneous environments. It includes a useful database heat map.
Hortonworks have also shared the
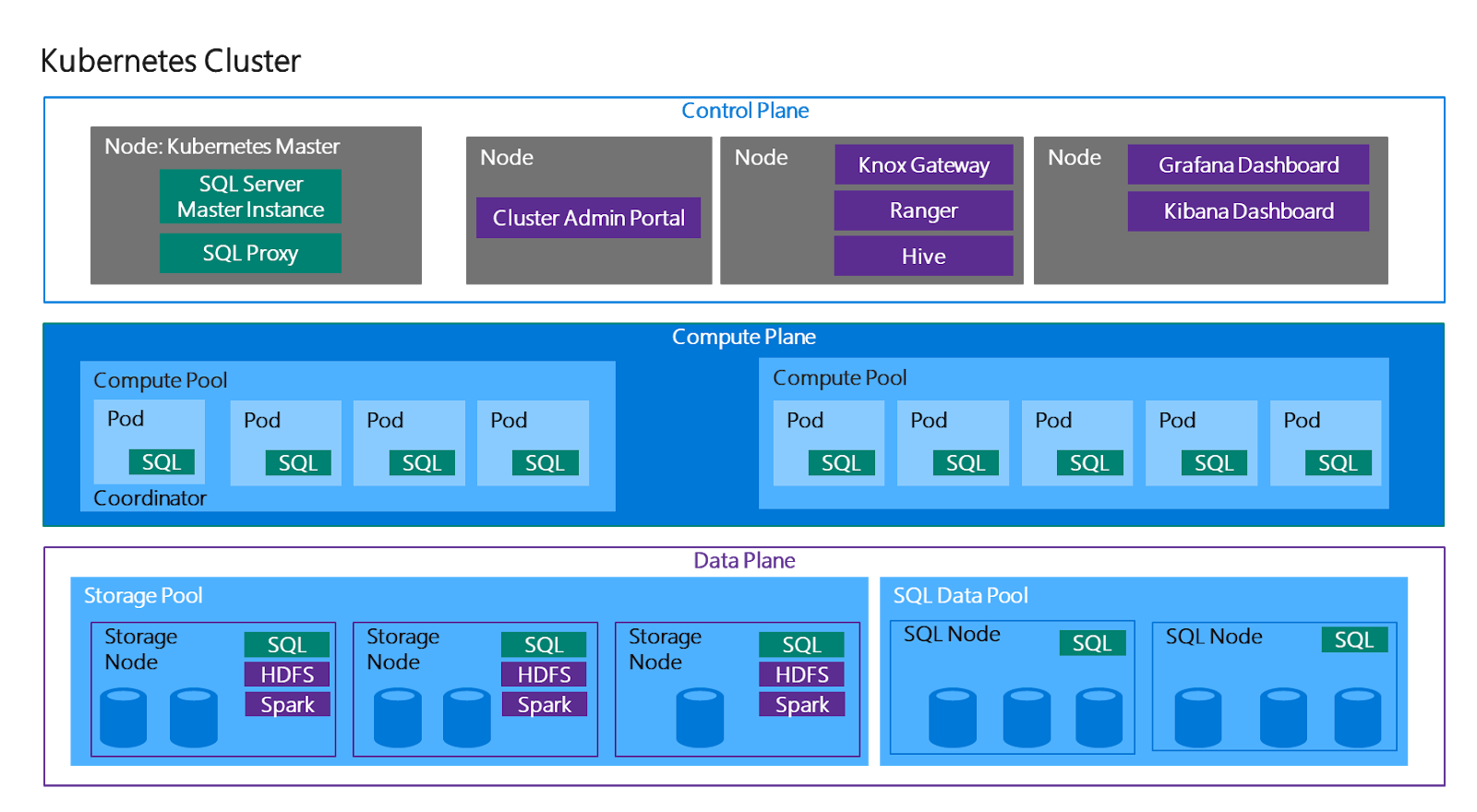
Open Hybrid Architecture Initiative, designed to enable big data workloads to run in a hybrid manner across on-premises, multi-cloud and edge architectures.
The Open Hybrid Architecture initiative will
- De-coupling storage, with both file system interfaces and an object-store interface to data.
- Containerizing compute resources for elasticity and software isolation.
- Sharing services for metadata, governance and security across all tiers.
- Providing DevOps/orchestration tools for managing services/workloads via the “infrastructure is code” paradigm to allow spin-up/down in a programmatic manner.
- Designating workloads specific to use cases such as EDW, data science, rather than sharing everything in a multi-tenant Hadoop cluster.